
Optimiser le consentement des visiteurs sur nos environnements digitaux est devenu en quelques années un enjeu stratégique majeur pour les sites web et les applications. Les CMP (Consent Management Plateform) se sont développées et ont largement été adoptées par les entreprises afin de fiabiliser la collecte du consentement, maintenir à jour la bannière, ou encore monitorer la performance de celle-ci (taux d’interaction, taux d’optin/d’optout etc.).
C’est justement sur ce dernier point que je souhaite aujourd’hui m’attarder. En effet les CMP proposent des outils de reporting en sein de leur interface afin d’avoir une première lecture de la performance de votre bannière.
Mais il peut arrivez que vous ayez besoin d’extraire ces données, afin d’aller plus loin dans votre analyse ou alors pour injecter la donnée dans un outil tiers (outil de Bi, Data Lake etc.). C’est dans ce contexte que les API proposées par certaines CMP peuvent devenir fort utiles.
Cependant, comme toute API, un travail de préparation préalable est nécessaire afin de comprendre comment celle-ci fonctionne (token, variables, format de retour etc.) et la manière dont nous ait retournée la donnée (imbrications du Json, systèmes d’id, recalcul de la donnée etc.). Je voudrais donc dans cet article vous partager mon retour d’expérience sur l’utilisation de l’API Trust Commander et vous donner un maximum de tips si vous envisagez vous aussi de l’exploiter.
Sommaire
Trust Commander et son outil Dashboard
L’API que nous allons donc voir dans cet article est celle de Trust Commander, la CMP proposée par Commanders Act.
L’outil propose par défaut un espace « dashboard », affichant les statistiques principales de différentes bannières créées sur votre compte :
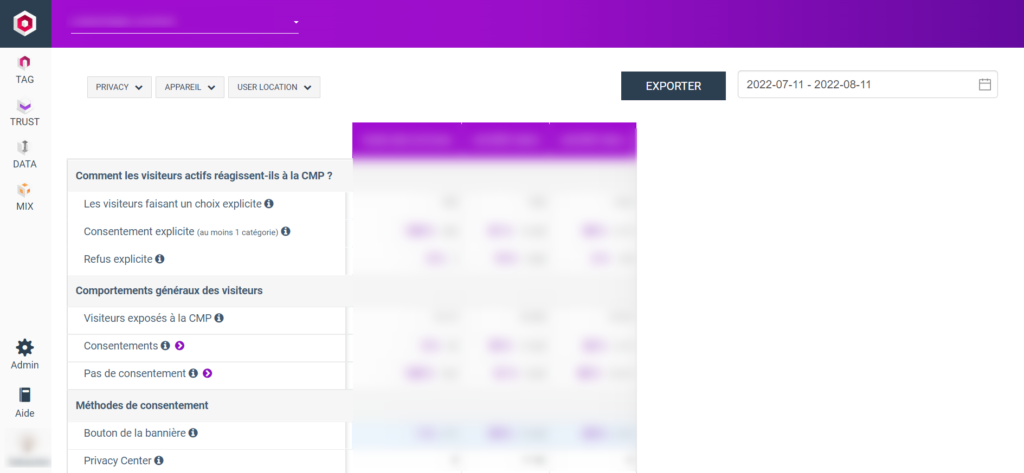
Même si les statistiques données sont claires, vous noterez la présence d’info bulles donnant une définition très précise de chaque chiffre (ex : »Taux d’interaction : Le nombre de visiteurs qui interagissent avec au moins un élément du 1ier écran »). Il existe également une page dédiée dans la documentation en ligne de Commanders Act.
On peut constater 3 filtres :
- Privacy (choix de la bannière)
- Appareil (choix des devices)
- User location (Union Européenne ou hors UE).
S’ajoute à cela un filtre de dates, avec des périodes prédéfinies (aujourd’hui, la semaine dernière, les 30 derniers jours) ou une période custom à sélectionner.
En complément des fonctionnalités préexistantes, l’API s’est avérée utile dans mon cas car j’avais besoin d’afficher des courbes d’évolutions de certains indicateurs, pouvoir les ventiler par device et par bannière, mais surtout d’injecter les données dans un outil tiers.
Fonctionnement de l’API trust Commander
L’API Trust Commander va nous donc permettre d’extraire la donnée de notre CMP à la granularité et la fréquence de notre choix.
Une page de l’aide en ligne lui est dédiée dans Commanders Act.
voyons maintenant ensemble comment l’exploiter !
Récupération de votre Token
Comme on peut le voir dans la documentation, la première étape pour nous sera de récupérer votre Token d’authentification. Sans cela, vous ne pourrez pas requêter l’API.
Pour l’obtenir il faudra contacter votre chargé de compte ou le support Commanders Act (support@commandersact.com). Si ça n’est pas déjà fait, je vous conseille d’effectuer cette demande dès maintenant afin d’obtenir votre token pour la suite de cet article.
Configuration de votre URL racine
L’API Trust Commander se compose d’une URL racine et de paramètres, faisant office de filtres.
La première étape pour nous va donc être de personnaliser l’URL en y ajoutant l’ID de votre compte :
https://api-internal.commander1.com/v2/siteId/privacy/statistics
Si vous ne la connaissez pas, vous pouvez la retrouver directement dans l’URL lorsque vous êtes dans Trust Commander :

Dans mon cas, l’URL racine devient ainsi :
https://api-internal.commander1.com/v2/1234/privacy/statistics
Configuration des filtres
Les filtres disponibles dans l’API Trust Commander sont exactement les mêmes que ceux présents dans l’interface, puisqu’elle requête elle même cette API.
Nous allons donc retrouver les filtres de dates, de devices, de campagnes et de localisation de l’utilisateur (tableau disponible dans la documentation Trust Commander) :

Ainsi, si je souhaite récupérer mes données pour le mois de juillet 2022, uniquement sur Desktop, pour les européens, mon URL sera alors (sans espace) :
https://api-internal.commander1.com/v2/1234/privacy/statistics
?token=123456789
&filter[begin_date]=2022-07-01
&filter[end_date]=2022-07-31
&filter[sup_filters][location][]=1
&filter[sup_filters][device][]=3
Vous pouvez tester votre API directement depuis votre navigateur, ou bien depuis un outil spécialisé. De mon côté j’utilise l’extension Thunder Client disponible dans Visual Studio Code. Pour que votre appel fonctionne correctement, vous devez obtenir une réponse 200 avec un JSON contenant des données :
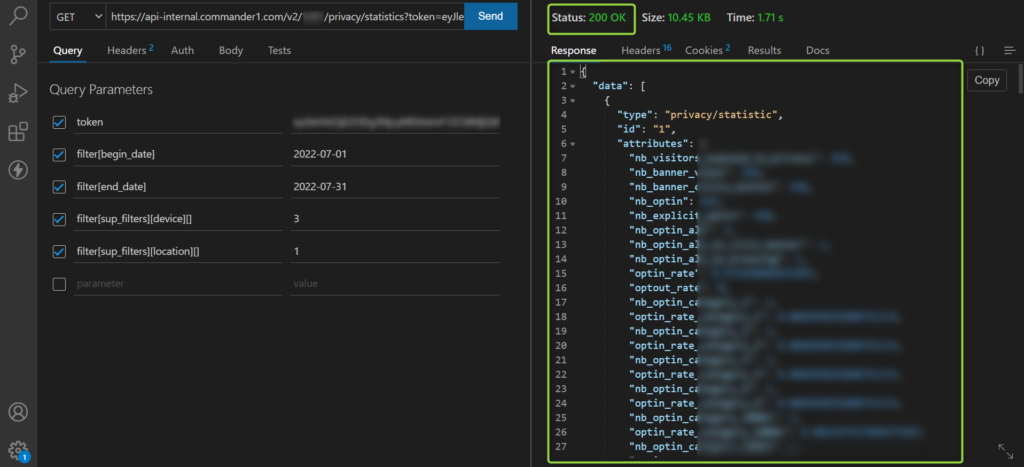
Il n’y a pas beaucoup plus à dire sur cette API très simple d’utilisation…à part peut-être le multi-filtres !
En effet si vous voulez filtrer sur plusieurs valeurs d’un même critère, par exemple isoler les mobiles et les tablettes pour les devices, vous devrez ajouter autant de fois le paramètre du filtre. Dans mon cas cela sera :
https://api-internal.commander1.com/v2/1234/privacy/statistics
?token=123456789
&filter[begin_date]=2022-07-01
&filter[end_date]=2022-07-31
&filter[sup_filters][location][]=1
&filter[sup_filters][device][]=1
&filter[sup_filters][device][]=2
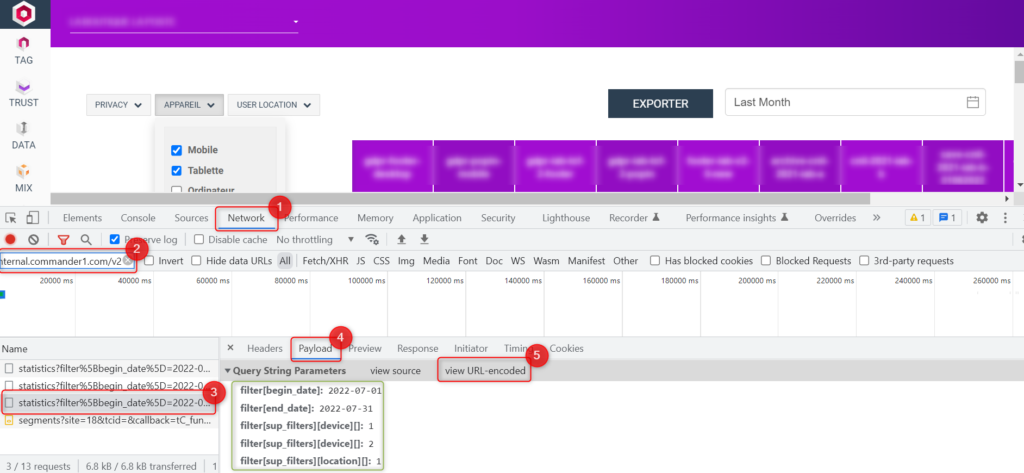
Dernière astuce, vous pouvez d’abord créer vos filtres dans le dashboard trust Commander, puis récupérer la configuration de l’appel directement dans le network de votre console, en filtrant sur « https://api-internal.commander1.com/v2 » , puis en allant dans payload et en cliquant finalement sur « View decoded » (illustation ci-dessous) :
Structure du Json Trust Commander
Avant de crier victoire et se lancer dans l’industrialisation du requêtage de l’API, il est important de comprendre la structure du JSON qui nous ait retournée. Pour visualiser cela, je vais utiliser l’outil Json Visio (vous pouvez en faire de même dans vos projets). Voici ce que cela donne :
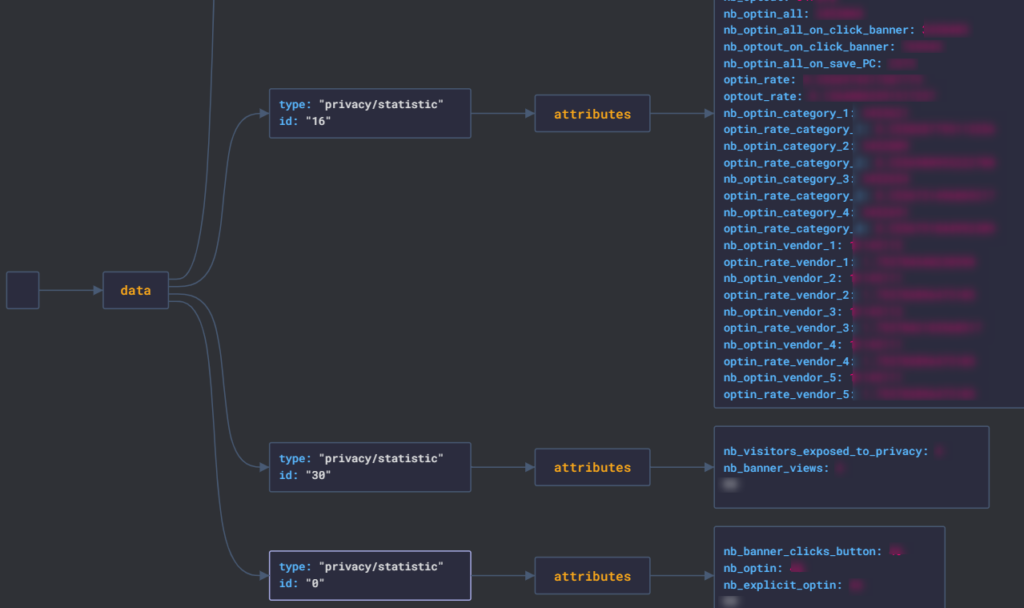
Nous avons donc un objet « data » contenant toutes les données. Celui-ci est constitué d’un tableau d’objets, contenant à chaque fois un type (ici « privacy/statistic » et un id). Chacun de ces objets représente une bannière Trust Commander, et au sein de cet objet, nous retrouvons un certain nombre d’attributs qui sont les données liées à la bannière.
Retrouver la correspondance entre le nom de la bannière et son ID
Comme vous l’aurez compris, nous n’avons pas directement le nom de la bannière, mais son ID.
Pour retrouver à quoi correspond l’ID de votre bannière, vous pouvez aller dans sa zone d’édition et rechercher dans l’URL la valeur présente après « settings » :
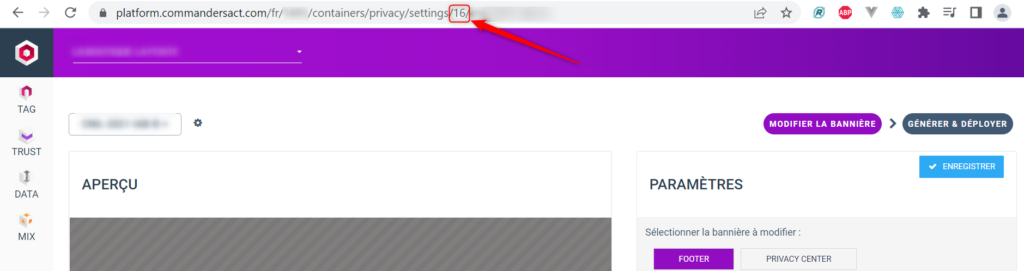
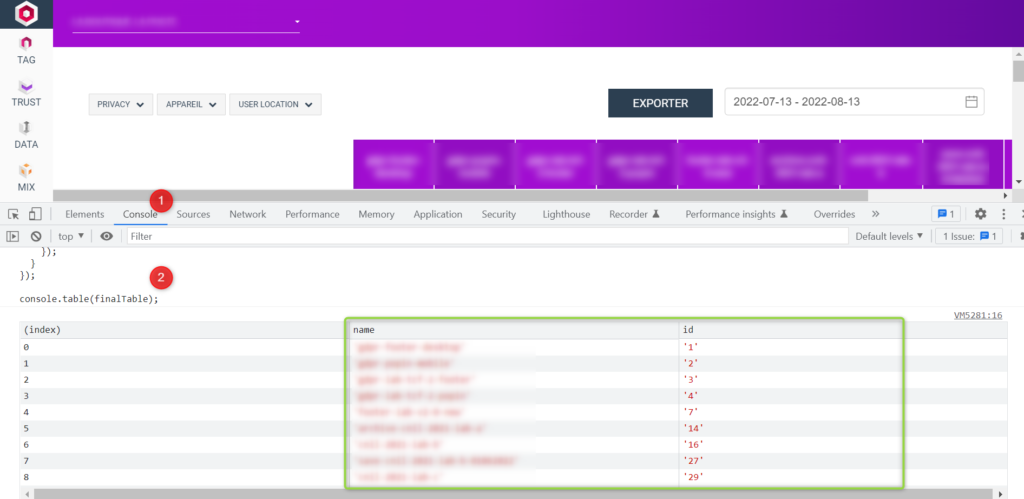
Pour récupérer toutes les correspondances en une seule fois, vous pouvez également exécuter ce petit code dans votre console, lorsque vous êtes dans le dashboard Trust Commander :
let table = document
.querySelector("#statistics_summary")
.querySelector("thead")
.querySelectorAll("th");
let finalTable = [];
table.forEach((banner) => {
if (banner.className) {
finalTable.push({
name: banner.innerHTML,
id: banner.className.split('-')[1]
});
}
});
console.table(finalTable);Voici ce que vous devriez obtenir :
Maintenant que nous avons pu traduire nos ID de bannières avec leur nom, nous pouvons nous attaquer aux données présentes dans ceux-ci !
Comprendre la signification des attributs
Une fois que nous sommes dans les attributs de la bannière, il n’y a plus de difficulté particulière, techniquement parlant. Il suffit maintenant de comprendre les correspondances entre les libellés et les définitions de chaque donnée dans le Dashboard Trust et le nom des attributs dans l’API.
Pour vous aider, voici une petite compilation des correspondances du dashboard et des attributs API (avec les définitions, si elle sont présentes) : Fichier Correspondance.
Comme vous le verrez, 2 typologies d’attributs seront probablement différentes dans votre cas : Les volumes d’optin sur les catégories (ex : « nb_optin_category_1 ») et les vendors (ex : « nb_optin_vendor_3 »).
En effet les catégories et les vendors sont définis par vous lors de l’élaboration de vos bannières. La liste est donc unique à chaque compte. Pour retrouver facilement les correspondances entre les ID et les noms des catégories/vendors, vous pouvez vous rendre dans les pages « Gestions des catégories et Gestion de partenaires de Trust Commander :
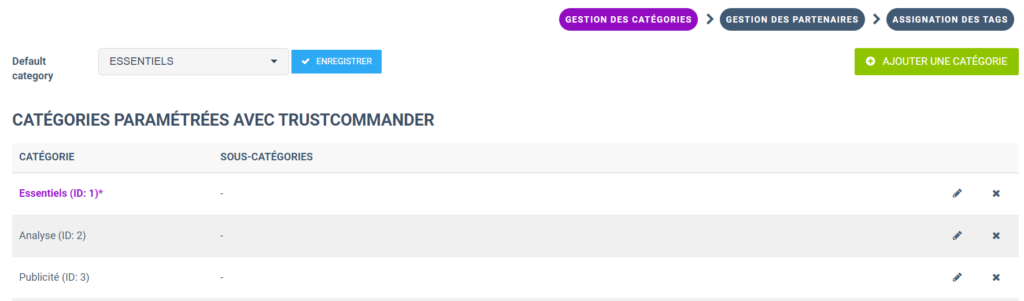
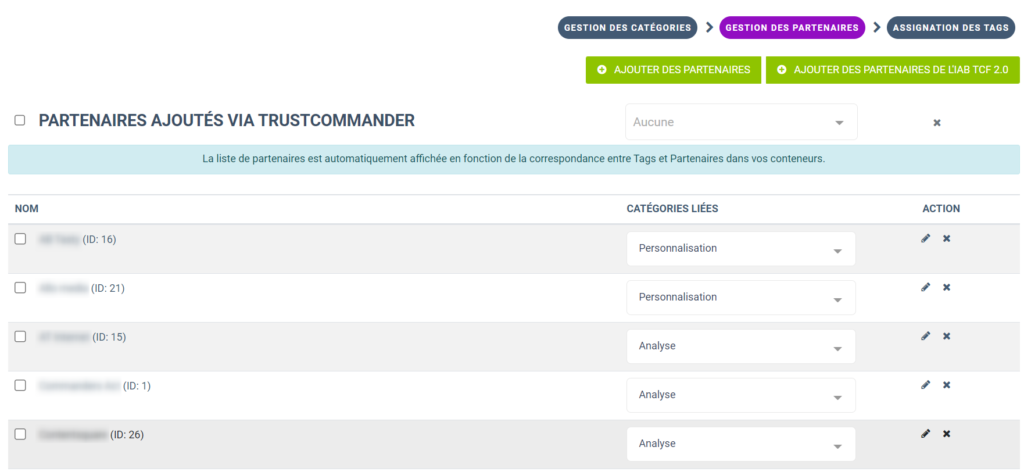
Vous avez maintenant normalement tous les éléments pour comprendre au mieux le contenu de ce JSON ! Il nous reste maintenant à requêter cette API de manière plus industrialisée.
Récupération de la granularité de données souhaitée en Python via l’API
Maintenant que nous avons réalisé notre premier appel et avoir compris le contenu de celui-ci, il nous reste à construire le code/process permettant de répondre à notre problématique.
Ce que nous souhaitons récupérer comme données
La première étape est de bien définir ce que nous souhaitons comme résultat final.
Dans mon cas je souhaitais récupérer pour toutes mes bannières l’ensemble des données disponibles dans un appel :
- Pour chaque jour depuis le 1ier janvier 2022
- Pour chaque Device
- Uniquement pour l’Union Européenne
Et pour réaliser cela, je fais le choix pour cet article d’utiliser le langage Python ! Si vous n’avez pas d’instance Python sur votre ordinateur, vous pouvez utiliser Le service de notebook en ligne de Google.
Réaliser un premier appel API en Python (guide pas à pas)
Avant toute chose, entrainons-nous à réaliser un appel simple. Nous allons utiliser cette API, qui est déjà dans le format dont nous aurons besoin :
- Sur une journée (le 01/07/2022)
- Sur un device précis
- Sur les données EU
https://api-internal.commander1.com/v2/1234/privacy/statistics?token=123456789&filter[begin_date]=2022-07-01&filter[end_date]=2022-07-01&filter[sup_filters][location][]=1&filter[sup_filters][device][]=3
Pour ce faire, nous allons utiliser la librairie requests et nous allons créer 2 paramètres :
- url, qui contiendra la racine de l’URL API
- params, qui contiendra la query string
On stock finalement le résultat retourné dans la variable ‘data’ via la propriété .content de requests.
Voici le code (j’ai tout de suite appelé l’ensemble des librairies dont nous aurons besoin dans le projet) :
import pandas as pd
import requests
import json
import numpy as np
import datetime
import time
url = "https://api-internal.commander1.com/v2/1234/privacy/statistics"
params = {'token': '123456789',
'filter[begin_date]': '2022-07-01',
'filter[end_date]': '2022-07-01',
'filter[sup_filters][device][]':3,
'filter[sup_filters][location][]':1
}
data = requests.get(url, params=params).content
data
Nous allons maintenant transformer ce texte en JSON via la librairie…json, rentrer dans l’objet ‘data’ (cf partie précédente) et tenter de pousser le résultat dans un dataframe Pandas.
data = requests.get(url, params=params).content
data = json.loads(data)['data']
pd.DataFrame(data)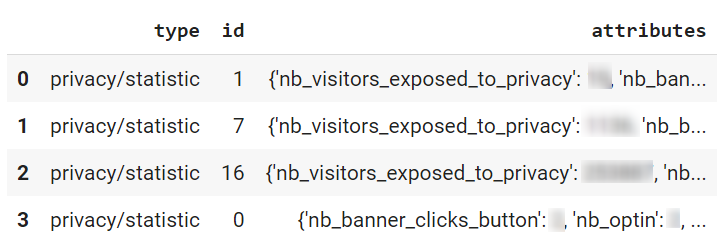
On commence à avoir un début de quelque chose mais cela ne va pas être encore exploitable. En effet toutes les données qui nous intéressent sont dans l’objet « Attributes » qui est encore sous format Json.
Nous allons donc plutôt créer un tableau, qui ira récupérer l’objet « Attributes » pour chaque valeur de notre tableau data. Nous poussons finalement le résultat dans un nouveau DataFrame :
data = requests.get(url, params=params).content
data = json.loads(data)['data']
listValues = []
for values in data:
listValues.append(values['attributes'])
pd.DataFrame(listValues)
Voilà qui est beaucoup mieux ! Nous avons maintenant chaque colonne correspondant à une métrique et chaque ligne correspondant à une bannière…mais laquelle ? L’information de l’ID de bannière de trouvait dans l’objet supérieur à attributes, nous n’avons donc pas cette information dans le tableau. Ajoutons lors de notre boucle une nouvelle propriété « banner id » qui viendra s’ajouter parmi les autres colonnes :
data = requests.get(url, params=params).content
data = json.loads(data)['data']
listValues = []
for values in data:
values['attributes']['banner id'] = values['id'] #ajout de l'id de la bannière dans l'objet 'attributes'
listValues.append(values['attributes'])
table = pd.DataFrame(listValues) # création de la variable table, qui stockera notre dataFrame
table[['banner id','nb_visitors_exposed_to_privacy','nb_banner_views']]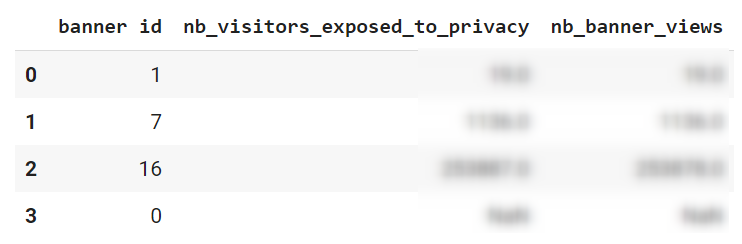
Notre premier tableau étant complet, voyons comment nous pouvons récupérer le reste des données.
Récupérer les données à la granularité souhaitée
Obtenir des données journalières
Nous l’avons vu, l’API trust Commander ne ventile pas les données à la granularité jour. Pour le réaliser, nous allons donc faire un appel pour chaque jour de la période souhaitée, puis reconstituer un tableau de données.
Nous créons une première variable ‘start’ à partir de la date de notre choix via la librairie Datetime. Nous créons une deuxième variable ‘end’ qui correspondra à la date actuelle moins une journée. Nous créons finalement une liste de dates pour chaque journée présente entre ‘start’ et ‘end’.
Libre à vous de personnaliser les dates selon vos besoins !
start = datetime.datetime.strptime("2022-08-15", "%Y-%m-%d") #création de la date de début
end = (datetime.datetime.today() - datetime.timedelta(days=1)).strftime('%Y-%m-%d') # date actuelle moins une journée
date_generated = pd.date_range(start, end) # création d'une liste de dates entre les 2 bornes
date_generated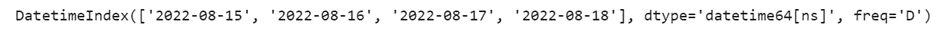
Il nous reste maintenant à intégrer cette liste dans une série d’appels API via une boucle. Voici le code complet :
import pandas as pd
import requests
import json
import numpy as np
import datetime
import time
url = "https://api-internal.commander1.com/v2/1491/privacy/statistics"
listValues = []
#Définition de la liste de date
start = datetime.datetime.strptime("2022-08-15", "%Y-%m-%d")
end = (datetime.datetime.today() - datetime.timedelta(days=1)).strftime('%Y-%m-%d')
date_generated = pd.date_range(start, end)
#Création d'une boucle à partir de nos dates
for dates in date_generated:
params = {'token': '123456789',
'filter[begin_date]': str(dates), #Dynamisation des dates dans l'appel API
'filter[end_date]': str(dates), #La date de début sera la même que la date de fin
'filter[sup_filters][device][]':3,
'filter[sup_filters][location][]':1
}
data = requests.get(url, params=params).content
data = json.loads(data)['data']
for values in data:
values['attributes']['banner id'] = values['id']
values['attributes']['date'] = dates #Ajout de la date parmi les colonnes du tableau final
listValues.append(values['attributes'])
table = pd.DataFrame(listValues) #compilation de l'ensemble des appels
table[['banner id','date','nb_visitors_exposed_to_privacy','nb_banner_views']]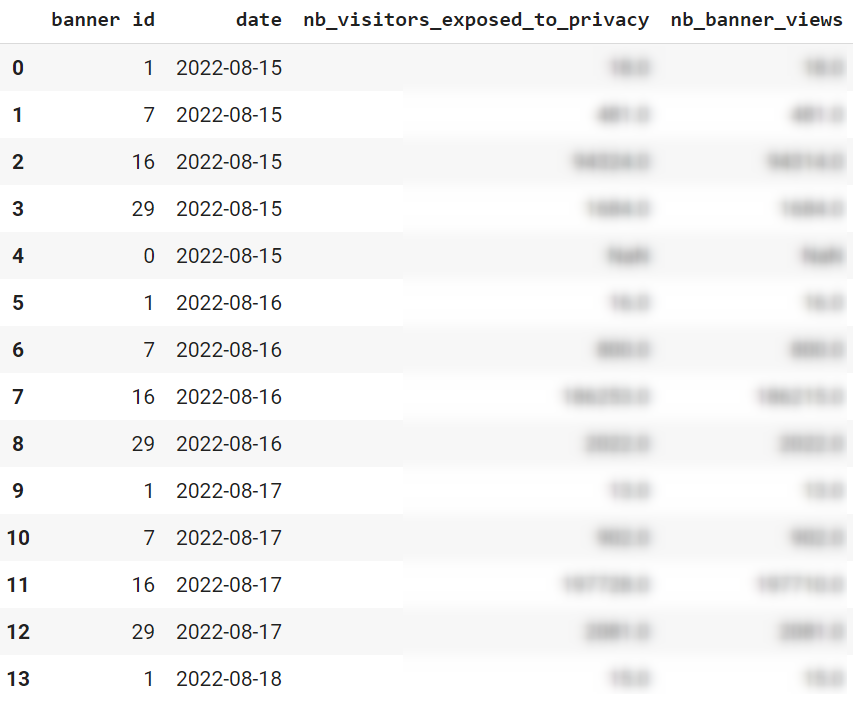
Obtenir des données pour chaque device
Pour rappel, les devices sont repartis dans 4 id différents (0,1,2,3). Il nous suffit donc de réappliquer la même logique que celle des dates, en incluant une nouvelle série de boucles sur ces ID :
import pandas as pd
import requests
import json
import numpy as np
import datetime
import time
url = "https://api-internal.commander1.com/v2/1491/privacy/statistics"
listValues = []
start = datetime.datetime.strptime("2022-08-15", "%Y-%m-%d")
end = (datetime.datetime.today() - datetime.timedelta(days=1)).strftime('%Y-%m-%d')
date_generated = pd.date_range(start, end)
#Création d'une liste des ID de device
devicesList = [0,1,2,3]
for dates in date_generated:
for device in devicesList:
params = {'token': '123456789',
'filter[begin_date]': str(dates),
'filter[end_date]': str(dates),
'filter[sup_filters][device][]':device, #Dynamisation du device ID dans l'appel API
'filter[sup_filters][location][]':1
}
data = requests.get(url, params=params).content
data = json.loads(data)['data']
for values in data:
values['attributes']['banner id'] = values['id']
values['attributes']['date'] = dates
values['attributes']['Device'] = device #Ajout du device parmi les colonnes
listValues.append(values['attributes'])
table = pd.DataFrame(listValues) #compilation de l'ensemble des appels
table[['banner id','date','Device','nb_visitors_exposed_to_privacy','nb_banner_views']]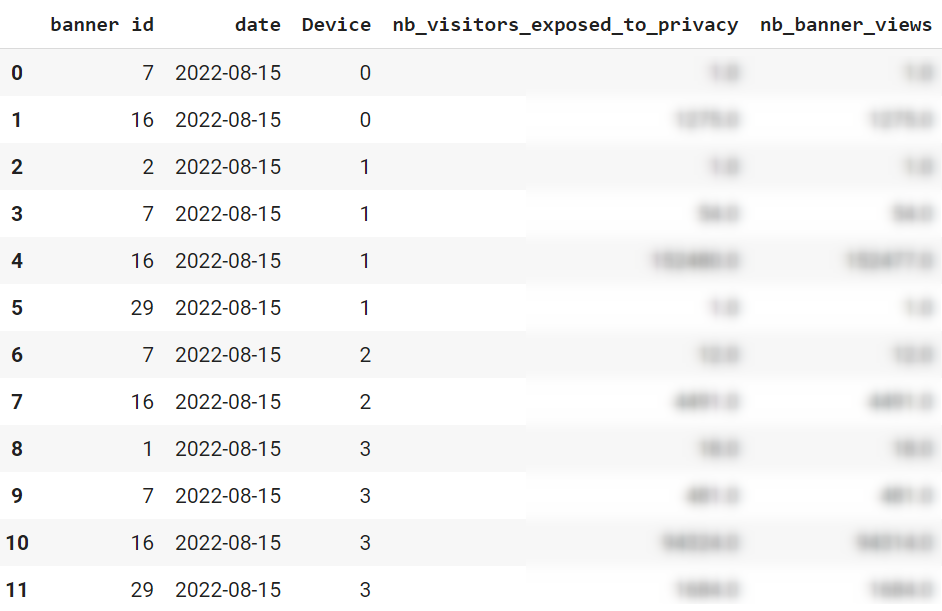
Renommer les colonnes et enregistrer les données
Comme nous avons déjà récupéré les traductions des colonnes dans un chapitre précédent, nous pouvons les renommer afin de les rendre plus compréhensibles. Je ne vais renommer ici que les colonnes génériques, mais libre à vous de vous occuper également des catégories et des vendors.
Pour cela j’utilise la méthode pd.read_csv() pour récupérer le tableau de correspondance que je vous ai donné tout à l’heure pour renommer mes colonnes via une boucle sur la méthode .rename()
J’enregistre finalement le résultat dans un fichier CSV :
table = pd.DataFrame(listValues) #compilation de l'ensemble des appels
translation = pd.read_csv('/files/trust/translate.csv', sep=";", decimal=',', encoding="latin1") #import de du tableau de correspondance des colonnes
for index, row in translation.iterrows():
table = table.rename(columns={row['Attribut Json']:row['NOM'].strip()}) #Renommage des colonnes
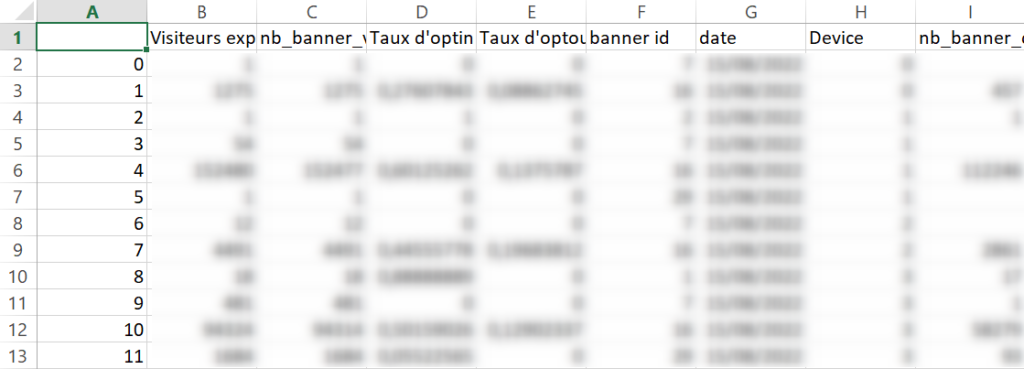
table.to_csv('/files/trust/trust_practice.csv', sep=";", decimal=',') #Enregistrement du tableau finalNous avons maintenant notre fichier CSV exploitable dans un outil de dashboarding :
Gestion des mises à jour des données
Nous pourrions très bien ré-exécuter le script sur l’entièreté de la période chaque jour afin de récupérer les données de la veille. Cependant cette méthode n’est pas très optimisée puisque vous allez chaque jour exécuter un très grand nombre de requêtes API pour récupérer uniquement une nouvelle journée de données.
Nous allons donc rédiger une variante de notre premier script, qui lancera uniquement les appels API depuis la dernière mise à jour du fichier puis l’écraser.
Nous allons appliquer la procédure suivante :
- Import du fichier d’historique
- Extraction de la date la plus récente présente dans la colonne ‘date’, qui deviendra la date de début des appels
- Exécution des requêtes API
- Fusion du tableau des nouvelles données avec le fichier historique
Voici le code adapté :
import pandas as pd
import requests
import json
import numpy as np
import datetime
import time
#Import de l'historique
history = pd.read_csv('/files/trust/trust_practice.csv', sep=";", decimal=',', index_col=[0])
#Extraction de la dernière date connue dans le fichier, qui sera la nouvelle date de début
start = datetime.datetime.strptime(history['date'].max(), "%Y-%m-%d") + datetime.timedelta(days=1)
end = (datetime.datetime.today() - datetime.timedelta(days=1)).strftime('%Y-%m-%d')
date_generated = pd.date_range(start, end)
devicesList = [0,1,2,3]
url = "https://api-internal.commander1.com/v2/1234/privacy/statistics"
listValues = []
#Condition permettant de vérifier si au moins une journée s'est passée depuis la dernière mise à jour
if len(date_generated) > 0:
for dates in date_generated:
for device in devicesList:
params = {'token': '123456789',
'filter[begin_date]': str(dates)[0:10],
'filter[end_date]': str(dates)[0:10],
'filter[sup_filters][device][]':device,
'filter[sup_filters][location][]':1
}
data = requests.get(url, params=params).content
data = json.loads(data)['data']
for values in data:
values['attributes']['banner id'] = values['id']
values['attributes']['date'] = dates
values['attributes']['Device'] = device
listValues.append(values['attributes'])
table = pd.DataFrame(listValues)
translation = pd.read_csv('/files/trust/Correspondance_db_api.csv', sep=";", decimal=',', encoding="latin1") #import de du tableau de correspondance des colonnes
for index, row in translation.iterrows():
table = table.rename(columns={row['Attribut Json']:row['NOM'].strip()})
table = pd.concat([history,table], ignore_index=True) #Fusion de la nouvelle table et de l'historique
table.to_csv('/files/trust/trust_practice.csv', sep=";", decimal=',') #Enregistrement du tableau finalAfin de ne pas avoir à lancer la mise à jour manuellement, vous pouvez utiliser un scheduler qui le lancera pour vous automatiquement sur un serveur.
Conclusion
Nous avons découvert à travers cet article comment comprendre et exploiter l’API de Trust Commander et obtenir le maximum de granularité dans nos données CMP. J’ai utilisé de mon côté Python mais vous pouvez tout à fait utiliser un autre système (autre langage, solution cloud, outil de BI).